-
Pytorch 튜토리얼 따라하기개발/딥러닝 2019. 3. 29. 15:48
예제로 배우는 PyTorch를 따라하며 정리한 내용이다.
코드 + 주석
import numpy as np N = 64 # Batch Size D_in = 1000 # Input Dimension H = 100 # Hidden Dimension D_out = 10 # Output Dimension # rand = 0 ~ 1 균일 분포 # randn = 가우시안 정규 분포 # randint = 정수 균일 분포 # Generate Random Data x = np.random.randn(N, D_in) # N by D_in y = np.random.randn(N, D_out) # N by D_out # Reset Weight Random w1 = np.random.randn(D_in, H) # D_in by H w2 = np.random.randn(H, D_out) # H by D_out # Iteration을 수행할 때 다음 point를 어느 정도로 옮길지 결정하는 것 # Large = Overshooting # Small = Local Minimum learning_rate = 1e-6 # 10^-6 for t in range(500): # Feed Forwarding : Calculate y_pred h = x.dot(w1) # matrix product h_relu = np.maximum(h, 0) # maximum of 0 ~ x, not negative y_pred = h_relu.dot(w2) # matrix product # calculate and print loss loss = np.square(y_pred - y).sum() # Mean Squared Error, 예측 값과 실제 값 차이의 제곱 print(t, loss) # BackPropagation grad_y_pred = 2.0 * (y_pred - y) # grad = 기울기 벡터장 grad_w2 = h_relu.T.dot(grad_y_pred) # T = Transposed Matrix 전치행렬, 행과 열을 바꾸는 것, matrix product grad_h_relu = grad_y_pred.dot(w2.T) grad_h = grad_h_relu.copy() grad_h[h < 0] = 0 grad_w1 = x.T.dot(grad_h) # Renew weight using Gradient Descent w1 -= learning_rate * grad_w1 w2 -= learning_rate * grad_w2흐름 구성
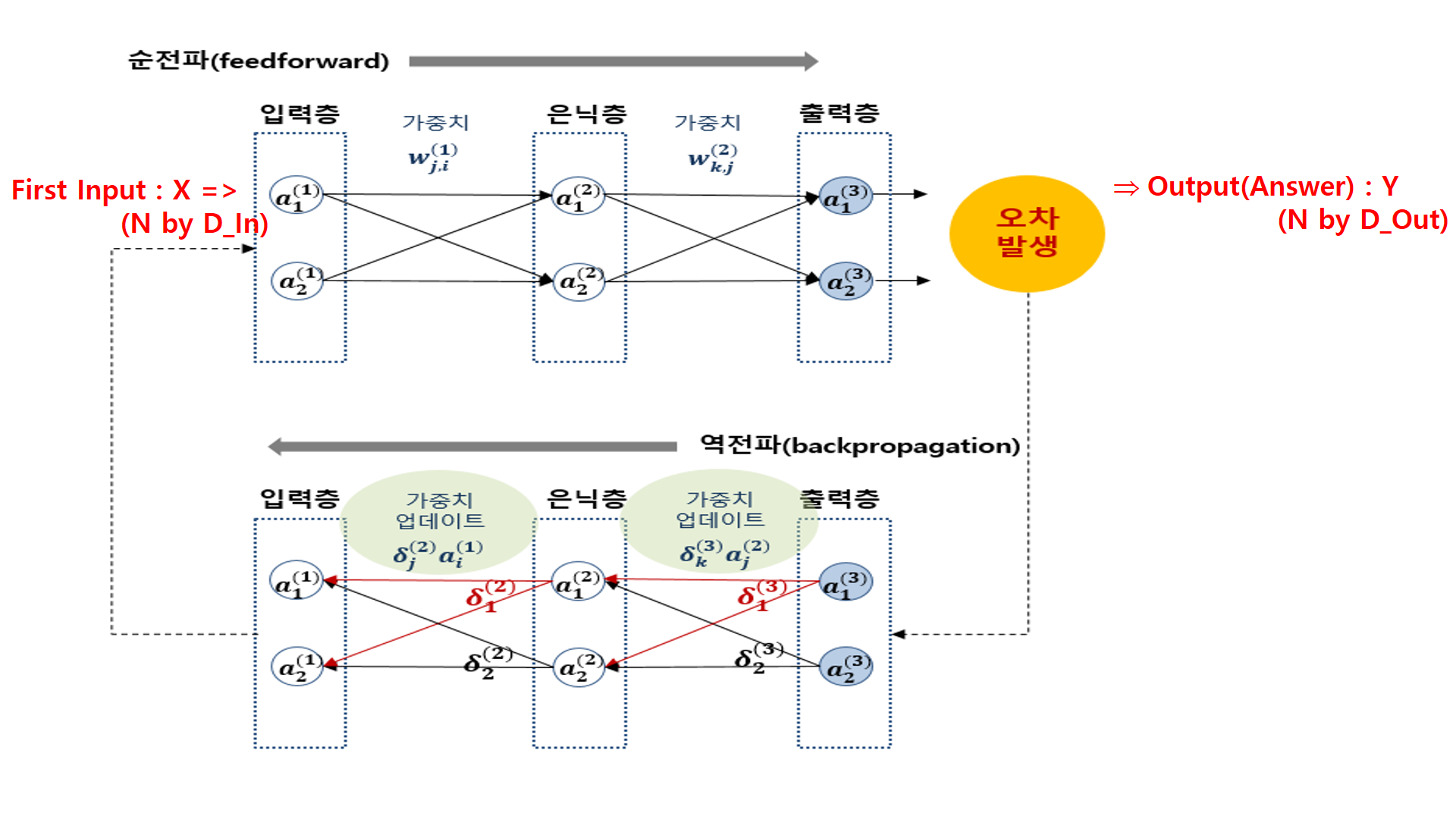
1. Data Input 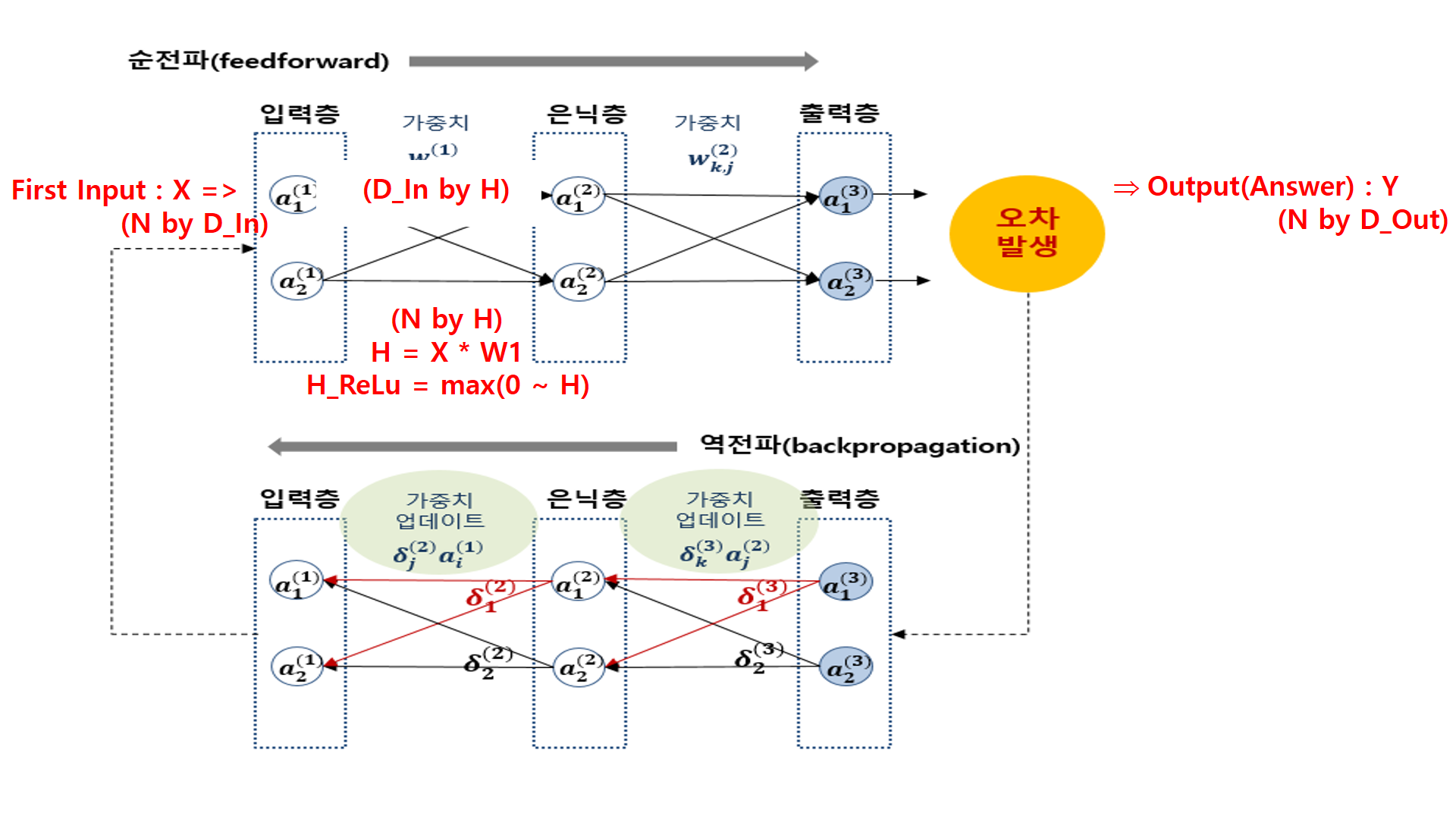
2. H, H_ReLu 구하기 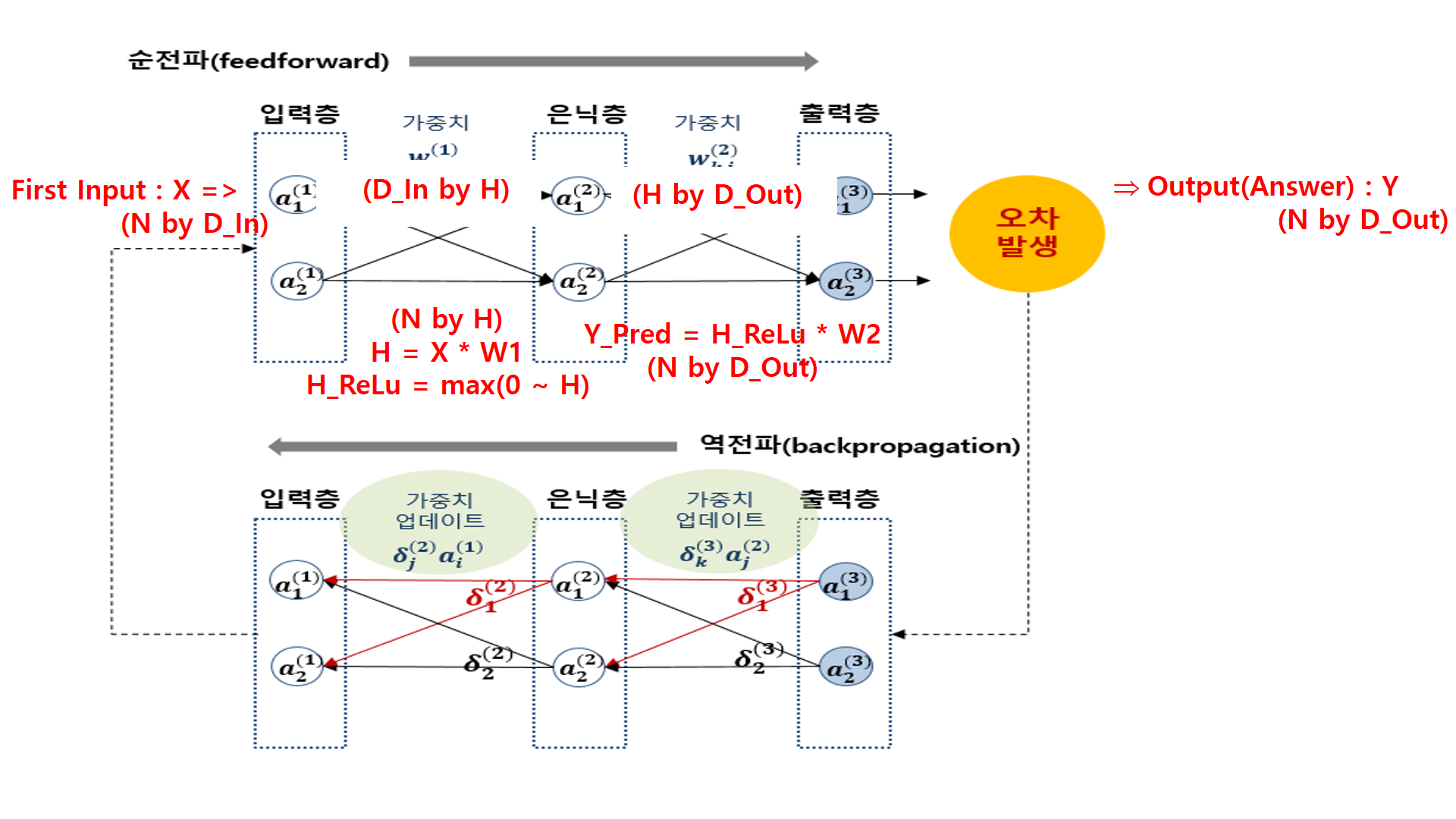
3. Y_Pred(예측한 답) 구하기 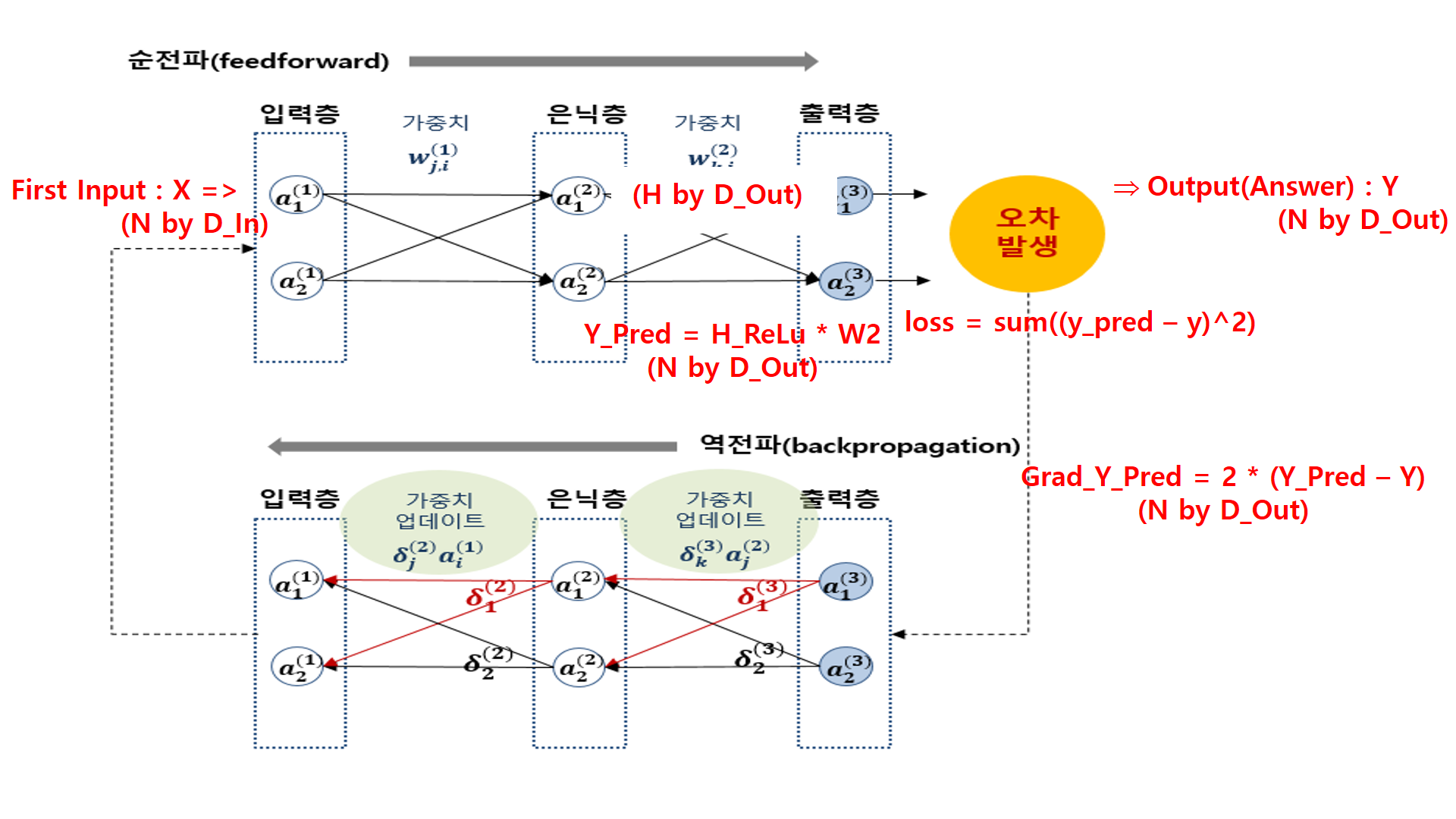
4. loss구하고 역전파 시작 
5. Grad_W2 구하기 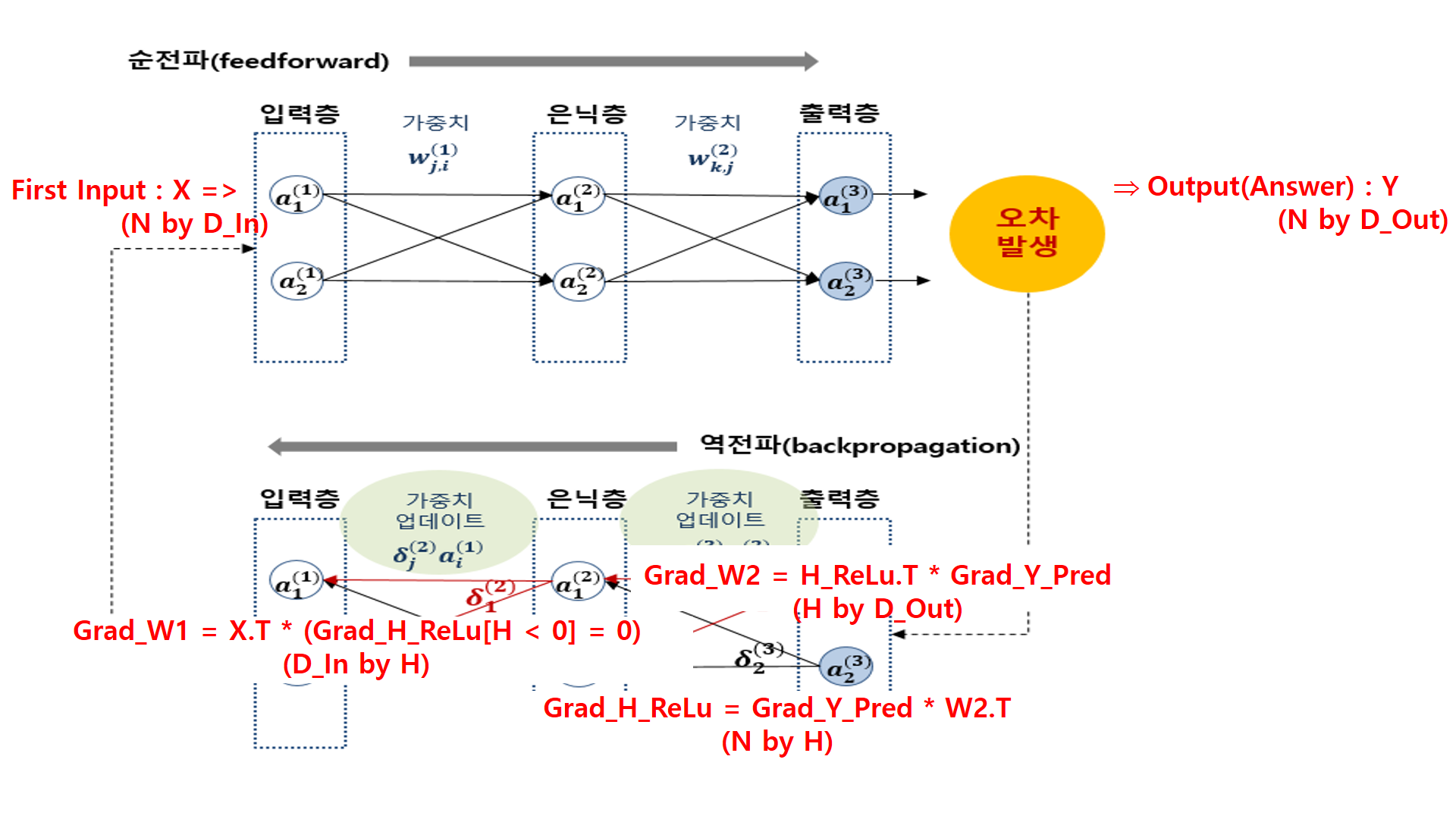
6. Grad_W1 구하기 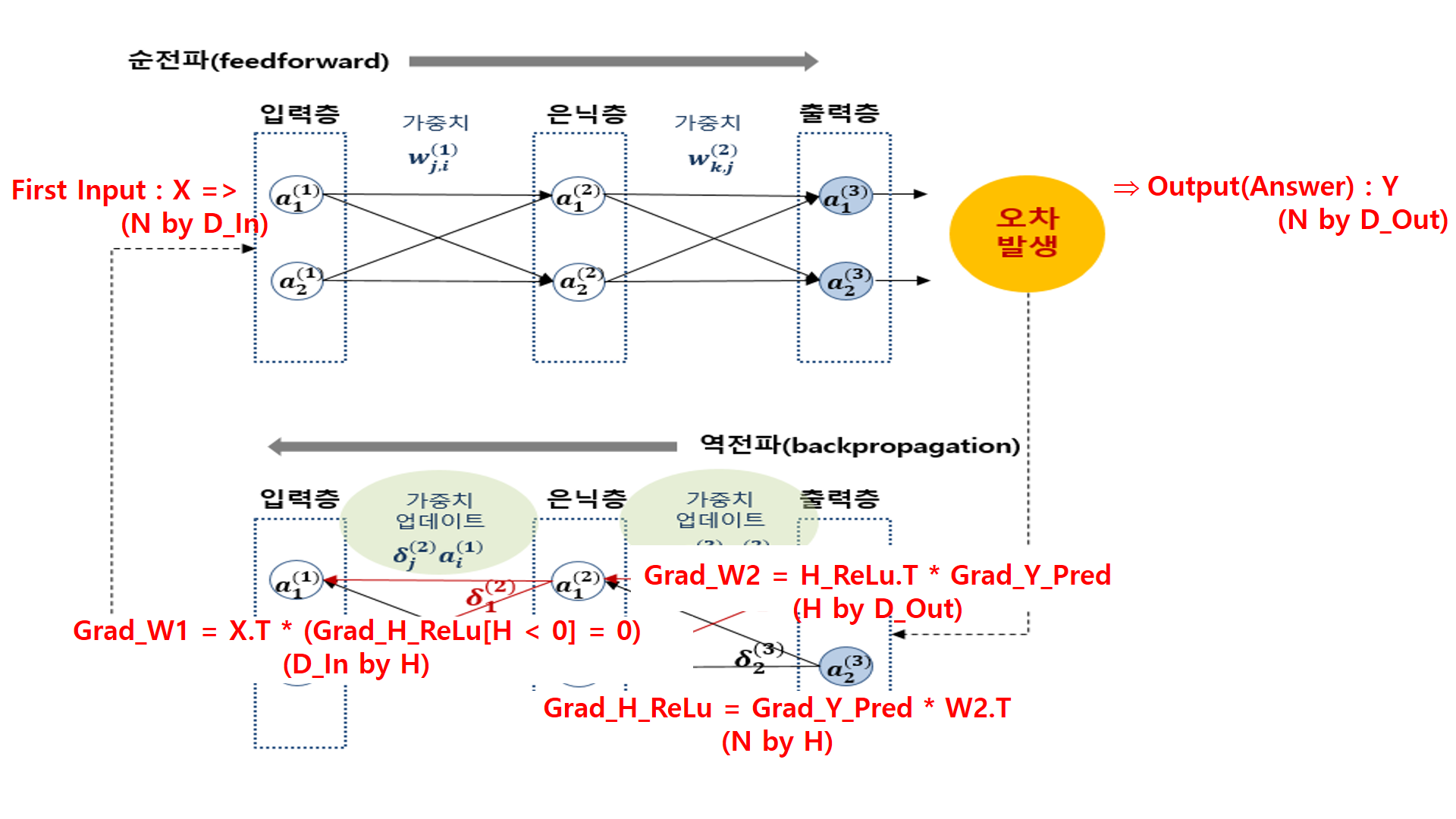
7. 구해진 W1, W2에 learning_rate 곱하여 가중치 수정하기 '개발 > 딥러닝' 카테고리의 다른 글
파이썬 GPU 선택하여 사용하기 (0) 2020.12.23 Transformers, sentencepiece 설치 에러 (0) 2020.12.18 Transformer-XL 자료정리 및 설명요약 (0) 2019.07.16 XLNet 자료정리 및 설명요약 (0) 2019.07.02 Pytorch RNN(LSTM, GRU) Multi gpu 사용하기 (0) 2019.04.05