-
Attention Mechanism(어텐션 메커니즘) 요약 설명, 조사프로젝트/NLP Core 2019. 4. 28. 00:11
-Attention Mechanism
1. 참고 링크
- Attention
- https://wikidocs.net/22893
- 어텐션 메커니즘과 transfomer
- Attention is all you need
- NLP with attention
- Attention? Attention
- The Illustrated Transformer
- Bert
2. 설명
-특정 벡터에 집중하여 성능을 높이는 기법으로 아래의 문제점을 해결
-기존 RNN으로 seq2seq을 풀 때 문제점
- 첫째, 하나의 고정된 크기의 벡터에 모든 정보를 압축하려고 하니까 정보 손실이 발생한다.
- 둘째, RNN의 고질적인 문제인 기울기 소실(Vanishing Gradient) 문제가 존재한다.
-핵심 아이디어
- I love you -> 나는 너를 사랑해 로 번역할 때, 인코더가 love로 만든 벡터가 디코더가 사랑해를 예측할 때 쓰는 벡터와 유사할 것이다. 즉, 사랑해를 예측할 때 love 벡터를 더 집중적으로 보는 것이다.
-Seq2Seq에서의 Attention
- 디코더의 특정 time-step의 output이 인코더의 모든 time-step의 output 중 어떤 time-step과 가장 유사한가
-Bi-LSTM에서의 Attention
- LSTM을 거친 모든 outputs(contextual matrix)과 LSTM의 최종 state(query)간의 Attention을 본다
- LSTM hidden cell의 마지막 Hidden State가 어떤 time에 영향을 많이 받았는가
-Self-Attention
- 한 단어가 한 문장 안에서 어디에 집중하는지 계산한다.

- 단어를 Embedding한 vector, X를 통해 query, key, value vectors를 만들어낸다.
- Attention(Q,K,V)=softmax(QKT√dk)V
- query가 각각의 key에 어느정도 attention을 둬야하는지 계산한다.
- key와 value는 attention이 이루어지는 위치에 상관없이 같은 값을 가진다.
- query와 key에 대한 dot-product를 계산하면 각각의 query와 key 사이의 유사도를 구할 수 있다.
- 이 후 softmax를 거친 값을 value에 곱해줄 때, query와 유사한 value일수록, 즉 중요한 value일수록 더 높은 값을 가지게 된다.
- q1 = x1 * Wq, k1 = x1 * Wk, v1 = x1 * Wv 이다.
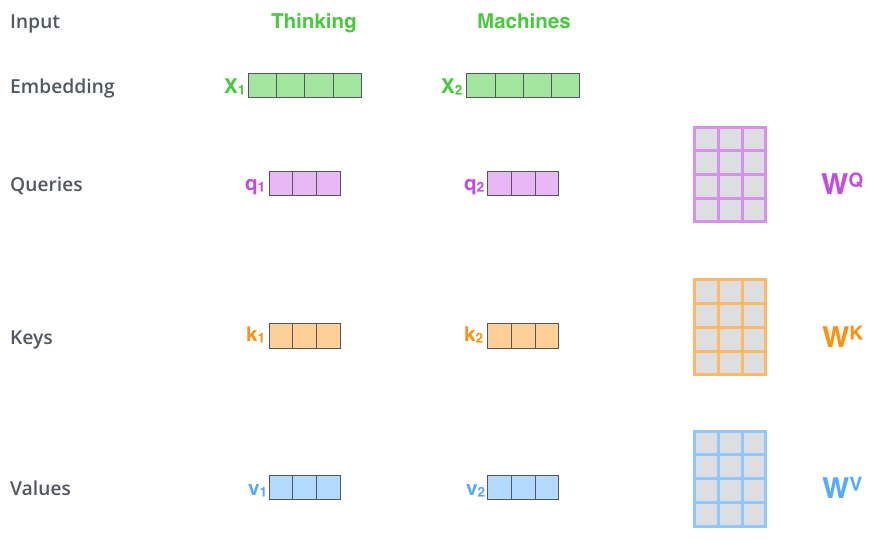

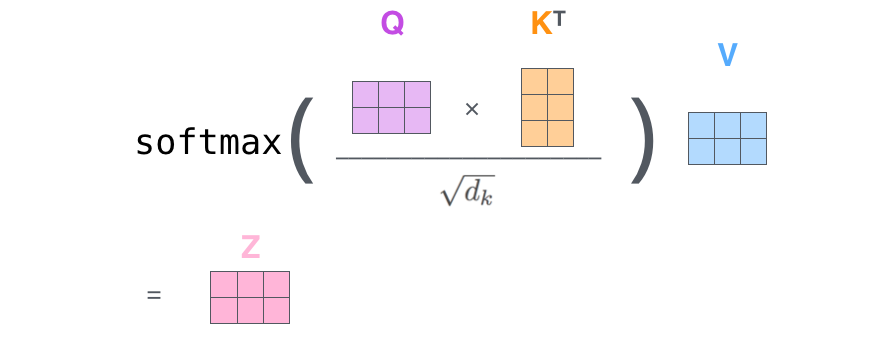
- 한 단어가 한 문장 안에서 어디에 집중하는지 계산한다.
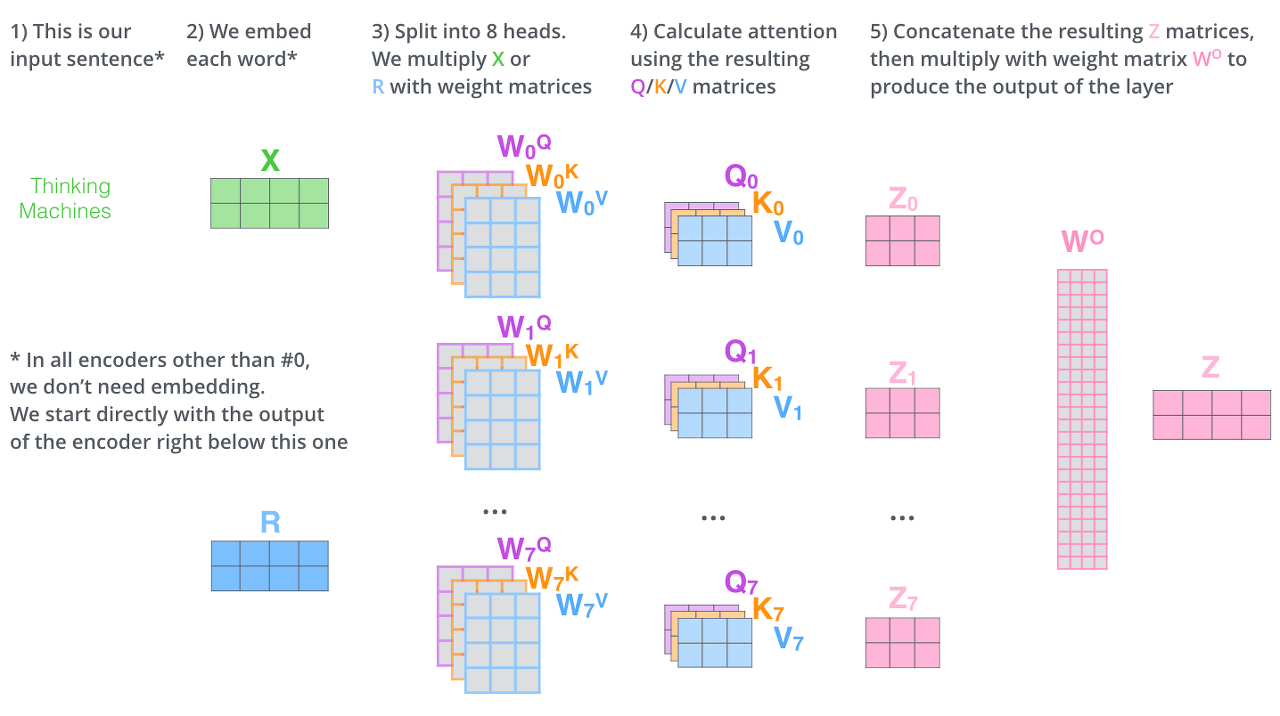
-Multi-Head Attention
- 동일한 query, key, value에 각기 다른 weight matrix W를 곱해 여러번 수행하는것

- 각각의 Attention Head 결과를 모두 합한뒤 가중치 Wo을 곱한다.
차원을 줄여준다.(vector 크기 조정)
(3칸 벡터의 크기는 64, 4칸 512입니. 댓글 감사합니다!)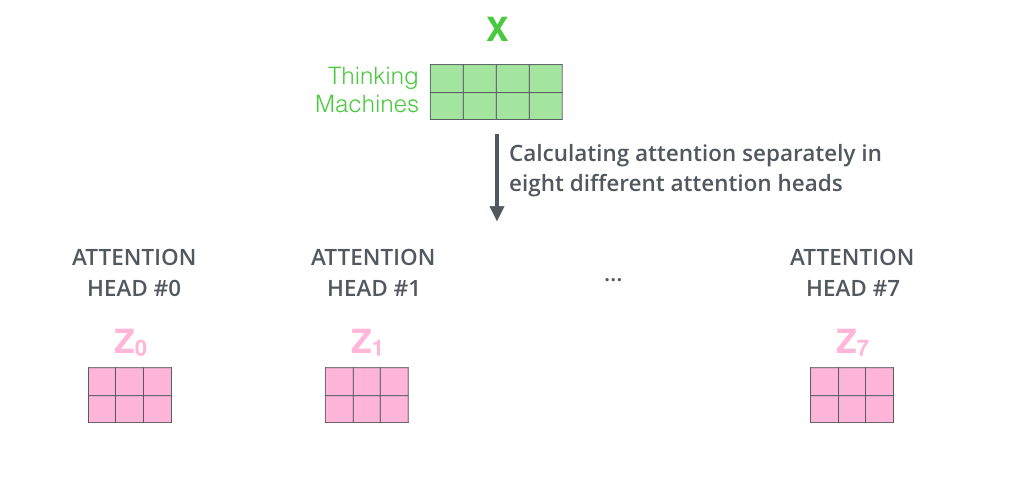
- 동일한 query, key, value에 각기 다른 weight matrix W를 곱해 여러번 수행하는것
-Positional Encoding
- Transformer는 Recurrence도 아니고 Convolution도 아니므로 Position 정보를 추가해줘야 한다.
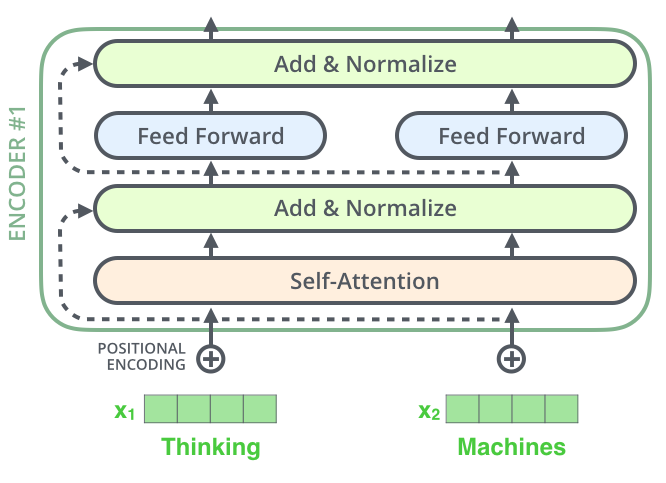
- Encoder와 Decoder의 input은 Positional Encoding + Word Embedding한 결과이다.
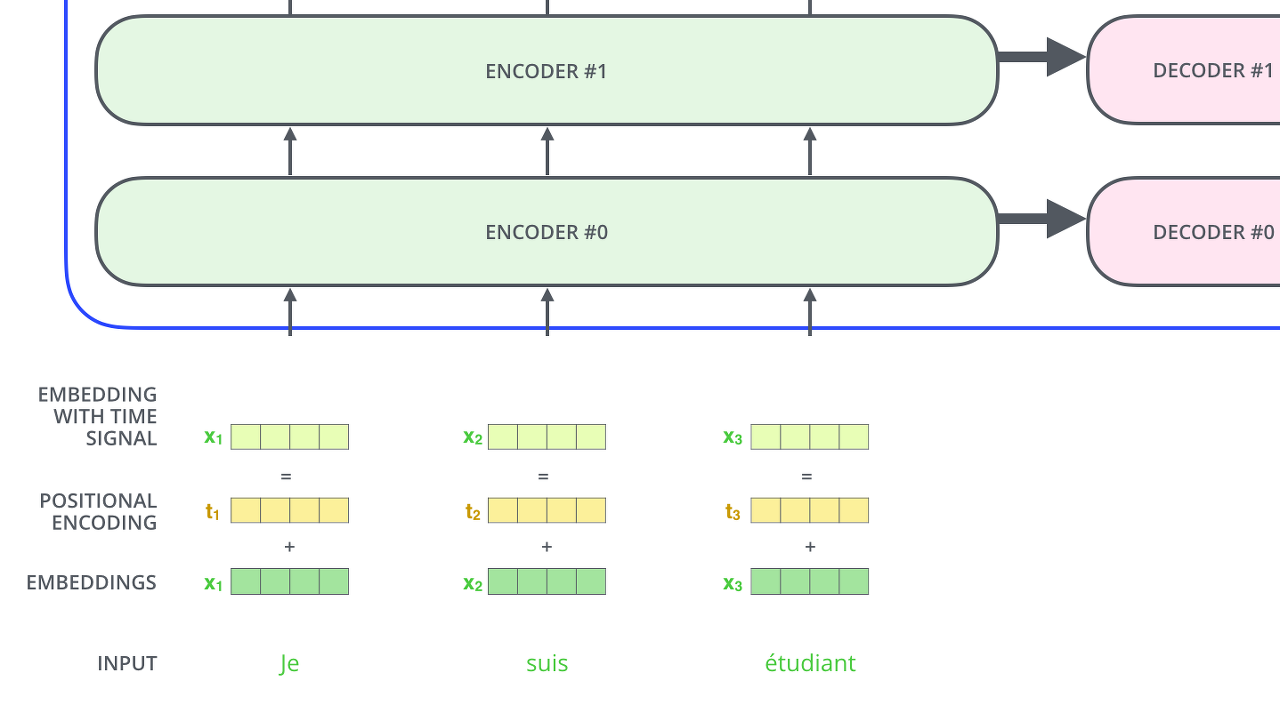
- Transformer는 Recurrence도 아니고 Convolution도 아니므로 Position 정보를 추가해줘야 한다.
-Masked Attention
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for # masked positions, this operation will create a tensor which is 0.0 for # positions we want to attend and -10000.0 for masked positions. adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0- 위는 Bert에서의 예시인데, Zero Padding에 대해서는 마스킹하여 어텐션하지 못하게 한다.
-전체 과정
'프로젝트 > NLP Core' 카테고리의 다른 글
Bert 요약 설명, 조사 (0) 2019.04.30 Seq2Seq 요약 설명, 조사 (0) 2019.04.28 Transformer 요약 설명, 조사 (0) 2019.04.18 1-2. DeepLearning(RNN) Result (0) 2019.04.07 1-2. 한국어 띄어쓰기 구현 - N-Gram (0) 2019.03.29